
Edge Processing and Data Conditioning
Making Data Useful Before It Leaves the Device
In the previous articles, we established two fundamental building blocks of a modern data collection system. Article 1 introduced the full sensor‑to‑cloud pipeline and the role of scalable storage such as Data Lakes, while Article 2 focused on sensors and signal acquisition, showing how physical reality is converted into raw digital data.
In this article, we move one step up the stack and look at what happens between sensing and connectivity: edge processing and data conditioning.
This layer is where raw measurements are transformed into reliable, efficient, and meaningful data — often before the data ever leaves the device. Just as importantly, it is data collection must coexist with the device’s primary responsibility: controlling a physical system.
Revisiting the Architecture
We continue to use the same high‑level architecture introduced earlier:
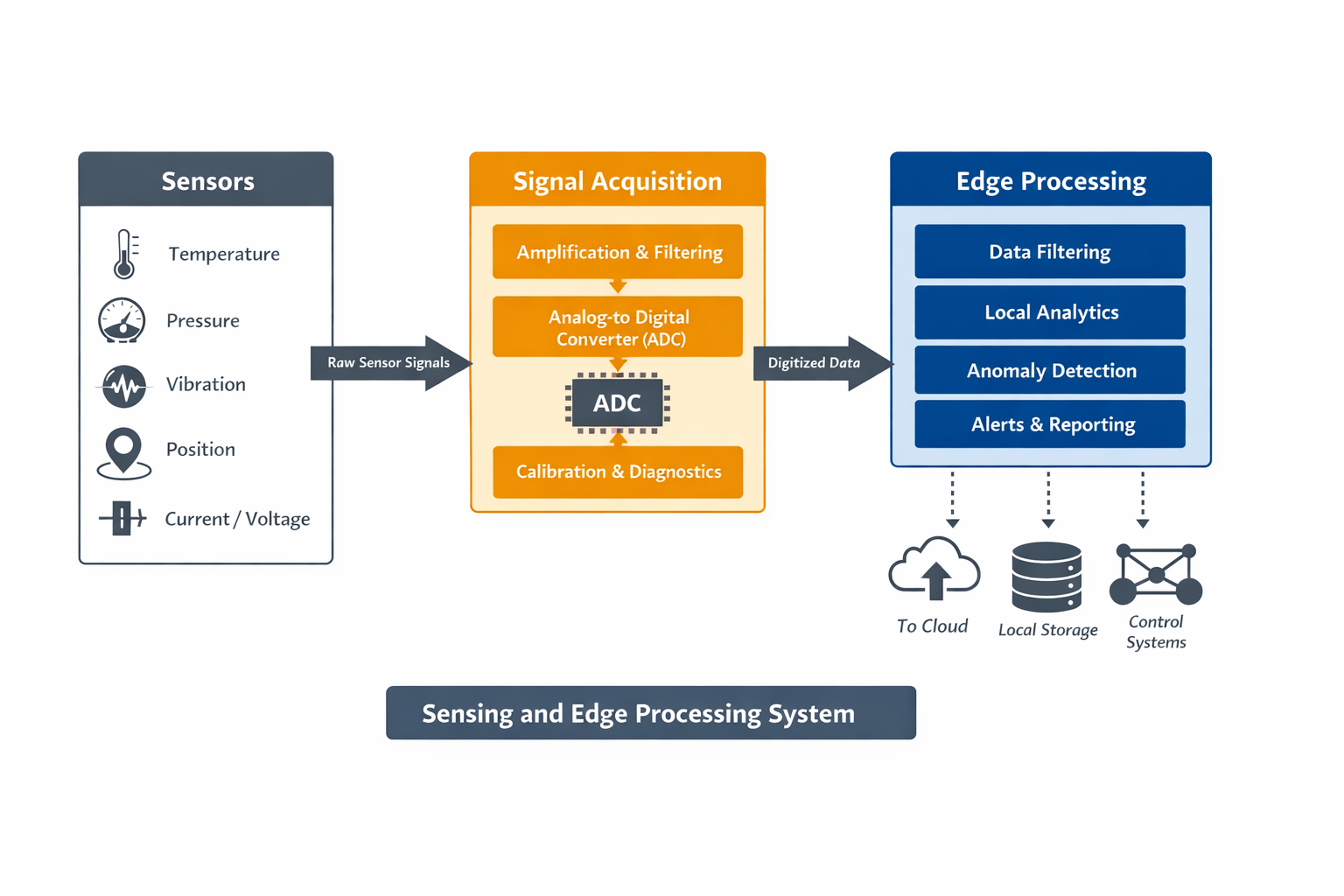
Figure: A high-level architecture showing how physical sensors, signal acquisition, and edge processing interact.
In Article 2, the focus was on the leftmost part of this diagram: sensors and acquisition. Now, the spotlight moves to the edge processing block, typically implemented on a microcontroller, system‑on‑chip, or industrial gateway.
Reusing the same architecture diagram reinforces an important point: the layers do not exist in isolation. Design decisions made at the edge directly affect cloud cost, system scalability, and long‑term data value. At the same time, edge processing is constrained by real‑time requirements and safety considerations that are often invisible at the cloud level.
Edge Processing in Control‑Centric Systems
In many real‑world products, the processing unit at the edge is not primarily a data logger. Its main task is to control a process: regulating a motor, maintaining temperature, managing power flow, or coordinating a machine sequence.
The control algorithm — often running in deterministic loops with strict timing guarantees — is the core function of the system. Data collection, while valuable, is usually a secondary responsibility that must never interfere with control stability, safety, or responsiveness.
This reality fundamentally shapes how edge processing and data conditioning are designed. Computation budgets are limited, memory is finite, and worst‑case execution time matters. Any data‑related processing must therefore be predictable, lightweight, and carefully integrated alongside the control logic.
What Is Edge Processing?
Edge processing refers to computation performed close to the data source, before transmission to backend systems. This computation is typically colocated with the control software and shares the same hardware resources.
Instead of forwarding raw sensor samples directly to the cloud, the edge layer performs local conditioning, validation, and interpretation of data. The goal is not to maximize data volume, but to extract useful information without compromising the primary control task.
Why Edge Processing Matters
Sending all raw sensor data directly to the cloud may appear attractive from a software simplicity perspective, but it rarely scales in control‑centric systems.
Bandwidth is often limited, especially in industrial or remote environments. Power consumption is critical for battery‑powered devices. Latency requirements may demand immediate local reactions, even when connectivity is unavailable. On top of that, cloud storage and processing costs grow quickly when high‑rate raw data is transmitted continuously.
Edge processing addresses these challenges by ensuring that only relevant, well‑conditioned data leaves the device, while time‑critical decisions remain local.
Data Conditioning at the Edge
One of the most common edge tasks is filtering and conditioning noisy sensor signals. Electrical interference, mechanical vibration, and quantisation effects are unavoidable in physical systems. Applying basic filtering locally improves signal quality before the data is used by the control algorithm or forwarded upstream.
Another key function is data reduction. A controller may sample signals at kilohertz rates to maintain stable control, but cloud systems rarely need that level of detail. By aggregating data over time — for example computing averages, extrema, or RMS values — the edge device dramatically reduces data volume while preserving the information that matters.
Edge processing is also well suited for event‑based logic. Many systems are only interested when something changes or crosses a defined threshold. Detecting these events locally allows the system to transmit concise, meaningful messages instead of continuous streams of samples.
Before transmission, data is typically normalised and enriched. Scaling values to engineering units, adding precise timestamps, and attaching metadata such as device identity or firmware version ensures that downstream systems can interpret the data correctly without additional context.
Edge Intelligence Beyond Simple Rules
As processing capabilities increase, edge devices are no longer limited to simple threshold logic. Pattern recognition, anomaly detection, and lightweight machine‑learning models are increasingly deployed alongside traditional control software.
Examples include identifying early signs of bearing wear from vibration patterns, detecting abnormal energy consumption, or recognising operational states of a machine. When implemented carefully, these techniques allow systems to react faster and reduce unnecessary data transmission, while still respecting real‑time constraints.
Reliability and Diagnostics
Because the edge device has direct visibility into sensors and local communication, it is also the best place to detect faults early. Sensor disconnections, implausible values, frozen signals, or internal communication failures can be identified immediately and reported explicitly.
This prevents faulty or misleading data from silently entering the Data Lake, where it could otherwise distort analytics and decision‑making.
Balancing Control and Data Collection
Designing edge processing always involves trade‑offs. Pushing more logic to the edge reduces bandwidth usage and cloud load, but increases firmware complexity and validation effort. Keeping the edge simple shifts the burden to the cloud, increasing operational cost and dependency on connectivity.
In control‑centric systems, the guiding principle is clear: data collection must adapt to the control system — never the other way around. Successful designs respect this hierarchy while still enabling scalable and future‑proof data architectures.
Edge Processing and Data Lakes
At first glance, edge processing and Data Lakes may seem contradictory. Edge processing reduces and filters data, while Data Lakes are designed to store large volumes of information.
In practice, they complement each other. Edge processing ensures that the data reaching the cloud is trustworthy, relevant, and well‑structured. The Data Lake then provides the flexibility to store, reprocess, and analyse that data as new questions and use cases emerge.
What’s Next in the Series
With conditioned data available at the edge, the next challenge is moving it reliably and securely to the cloud.
In the next article, we will focus on connectivity, protocols, and transport — and how to move data from edge to cloud without compromising integrity, security, or control performance.